世界中の気象データは、数分ごとに膨大な量が記録・保存されています。これらのデータを効率的に保存するために、grib2 ファイル形式が使用されています。これは、データのエンコードおよび圧縮にさまざまな方法を使用するバイナリファイル形式であり、気象データのようなグリッドタイプのデータを非常に効率的に保存できます。例えば、15 メガバイトのファイルには1 億以上のデータポイントを格納されています。
しかし、このように最適化されたファイル形式は、データ構造の解析に時間がかかります。また、異なる気象機関がそれぞれ独自のバージョンを採用しているため、オンラインで入手できるツールでは正しく読み取れないこともあります。さらに、オープンソースのソリューションでは処理速度が遅く、大規模なデータ処理に対応できない場合もあります。
そこで本記事では、Python のみを使用してgrib2データを高速に読み込み、可視化、解析するためのベースとなるファイルリーダーを構築する方法をご紹介します。このリーダーを活用すれば、クラウド環境で全球規模の地理空間データを解析できるFusedにより、日本全土をカバーする高解像度降水ナウキャストデータをリアルタイムで可視化、解析できるようになります。
◾️ grib2ファイルの解析手順
- grib2ファイルを開く
まずはgrib2ファイルを開き、すべてのバイト列を変数に読み込みます。 - データ構造を説明するドキュメントを取得
データ提供者がドキュメントを提供していない場合は、ECMWFの以下のページを参照してみましょう。https://codes.ecmwf.int/grib/format/grib2/ - データ構造を読み取る
grib2 ファイルは 9 つのセクション(0-8)で構成されており、それぞれの役割を理解する必要があります。例えば、データの最初の 4 バイトは Ascii 文字 “GRIB” で始まり、ファイルの最後のバイトは“7777”で終わる仕様です。(セクション0、オクテット 1-4 に記載)https://codes.ecmwf.int/grib/format/grib2/sections/0/
ドキュメントに従ってセクションごとに正しいバイト数で読み取ります。(https://codes.ecmwf.int/grib/format/grib2/sections/8/ )
これで grib2 ファイルからすべてのデータを正しく読み取ることができます。しかし、作業はまだ終わりではありません。次のステップでは、前の手順で抽出した情報を使用してデータを再構築します。 - データの再構築
読み取ったデータを、以下の情報を持つ二次元リストとして再構築します。最終的な出力は、以下の値を持つ二次元リスト(グリッドごと)となります。
- 緯度
- 経度
- 予測時間
- デコードされたデータ値
Pythonのpandas を使えば、データフレームとしてデータを整理し、正しくデータが処理できているか確認できます。データの解凍には、”numba” や “cython” などの低レベルライブラリを使用すると、パフォーマンスがさらに向上します。
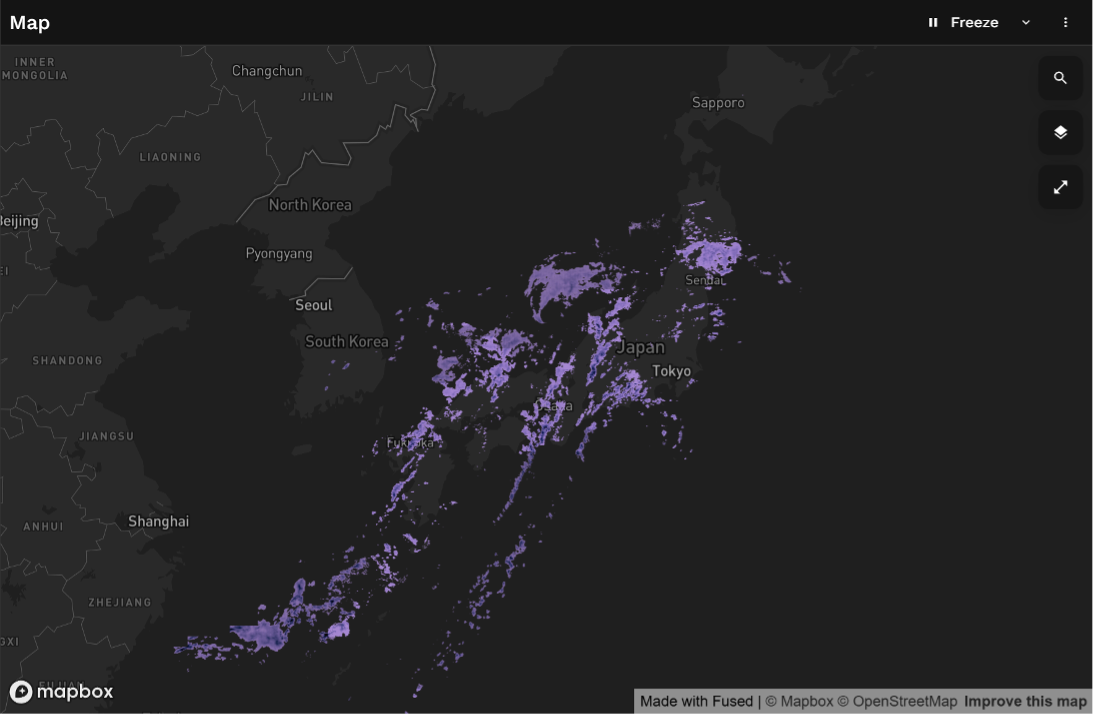
以下の例では、データフームとして格納したデータをFusedを使って可視化しています。データ値をフィルタリングして、データを見やすいように加工しています。
grib2 のデータローダーをゼロから作成するのは大変ですが、気象データを頻繁に扱う場合には、必要不可欠な作業です。私たちが開発したプログラムとFusedを組み合わせれば、全国規模のデータを数秒で読み取り処理できるデータパイプラインを作成することができます。
気象データを日本全国規模で可視化、解析をして、リアルタイムサービスをお考えの方は弊社に是非ご相談ください。